머리속에 다시금 새기기 위해 정리가 필요하여 남겨봅니다.
1. HDFS
- Hadoop Distributed File System의 약자. 빅데이터를 안전하게 저장하기 위한 파일 시스템.
- 2003년도에 The Google File System으로부터 시작되었고 이 파일 시스템은 빅 데이터를 처리해야하므로 기본적으로 확장성 있게 설계되었으며, 큰 규모로 분산 저장/복제가 가능하도록 설계되었습니다.
- 많은 서버들이 분산으로 데이터를 저장해야 하므로 각각의 서버의 고장으로부터 안전할 수 있도록 fault-tolerance가 고려되어있고 여러명의 사용자로부터 처리요청을 받게 되므로 전체적인 성능이 멀티테넌시 환경에서 높게 나오도록 설계되었습니다.
- low latency보다는 high throughput 중점으로 되어있다. 즉, 작은 파일을 대량으로 처리하는 것 보다 큰 파일을 배치로 처리하는데 효율적이라는 의미입니다. 따라서 자동적으로 실시간 처리보다는 한번에 많은 작업을 처리하는 배치 처리에 맞게 구성이 되어있는 것이죠.
- 또한, HDFS에 저장된 데이터 블록은 immutable합니다. 이 말은 HDFS가 WORM(Write-Once, Read-Many)라는 말과도 일맥상통합니다.
- MR을 통해 분석되는 파일들은 수정이 필요하지 않고, 중간결과 파일도 독립적으로 저장됩니다. 그 뿐만 아니라 HDFS에서는 replication도 지원하는데, 수정 작업이 들어올 경우, 분산되어 있는 모든 replica를 찾아서 내용을 수정해야 하기 때문입니다.
2. Architecture
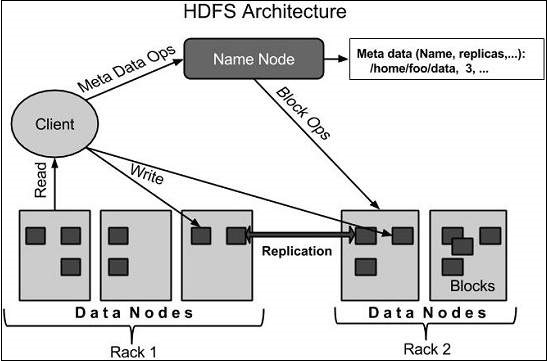
- HDFS의 기본 구조는 위 그림과 같이 구성되어 있는데, 크게 네임 노드와 데이터 노드로 나눌 수 있습니다.
1) 네임 노드(Name Node)
- HDFS에 저장된 데이터의 모든 메타정보를 메모리에 관리하고 있다가 사용자의 요청이 있을 시에 빠르게 전달합니다.
- 메타데이터는 파일 시스템의 디렉터리 이름과 구조, 파일 이름과 해당 파일을 여러 블록으로 나눈 목록을 갖고 있습니다. 이 목록으로 실제 데이터 노드에 저장되어 있는 데이터 블록을 찾아갈 수 있습니다. 저장되는 메타데이터의 종류 대해 조금 더 살펴보면
- 디렉토리 구조 : HDFS의 디렉토리 구조도 일반 파일 시스템과 동일하게 트리 구조로 되어있습니다. 하지만 실제로 디렉토리를 생성하면 메타데이터에만 존재하고 데이터 노드에는 아무 일도 발생하지 않습니다.
- 파일 : HDFS의 파일도 일반 파일 시스템과 동일하게 크기, 생성 시간, 권한, 소유자, 그룹 등과 같은 정보를 갖고 있습니다.
- 블록 : HDFS는 하나의 파일을 일정한 크기로 쪼개서 데이터 노드에 나누어 저장하는데 이를 블록이라고 합니다. 이렇게 나누게 되면 큰 파일도 손쉽게 나눠서 저장할 수 있으며, 후에 특정 파일에 대한 처리를 할 때에도 커다란 파일을 메모리에 다 올리지 않고, 작은 블록만을 메모리에 올려서 처리하는 일이 가능해집니다. 블록의 크기는 기본적으로 64M이며, 블록으로 파일을 나누었으므로 그 순서 또한 네임 노드에 함께 저장됩니다.
- 블록의 크기에 따른 장/단점 : 블록의 사이즈를 크게 결정할 경우, 클라이언트와 네임 노드의 통신 횟수가 줄어듭니다. 하나의 파일을 저장하기 위해 각 블록을 요청할 때마다 네임 노드와 통신을 해야 하는데, 블록 크기가 크기 때문에 그 만큼 블록의 갯수는 줄어들게 되기 때문입니다. 이 때문에 네임 노드의 부하가 줄어들게 됩니다.
- 또한 블록이 커지게 되면 replica등의 정보도 줄어들어 메타데이터의 크기도 줄어들게 되고 이는 사용 메모리 공간이 줄어드는 결과로 나타납니다. 하지만, 사용자 데이터를 저장하기 위해서 큰 블록을 할당했는데, 작은 파일만 쓰게 된다면 해당 블록은 파일 사이즈 만큼만 할당되어 기본 크기보다 작아지게 되는데 예를 들어, 기본값으로 64MB의 블록 크기를 갖는 시스템에서 32MB의 파일 4개가 각각의 블록에 저장되면 HDFS블록은 4개가 필요하게 되고, 블록들을 위한 메타데이터도 4개가 생성됩니다. 하지만 128MB파일이 들어오면 2개의 HDFS블록만 생성되면 되겠죠. 이와 같이 블록의 크기가 크게 되면 불필요하게 HDFS블록을 생성해야 하는 문제가 있고 이로 인하여 부하가 발생할 수 있다고 합니다. (물론 HAR등과 같이 다른 파일을 하나의 블록에 저장하도록 하는 메카니즘도 존재합니다.)
데이터 노드 정보 : 블록들을 잃어버리지 않기 위해 replica를 생성하는데 이런 블록들이 저장되는 데이터 노드의 위치 정보가 저장됩니다.
데이터 노드들의 상태 정보를 유지하고 관리합니다.
현재 HDFS에 등록되어 있는 데이터 노드의 목록과 현재 동작이 가능하지 등을 지속적으로 heartbeat를 통해 관리하게 되고 이 정보를 이용해서 새롭게 추가되는 데이터 블록이 어디에 저장되어야 하는지, replication이 제대로 이루어지고 있는지 등을 알아낼 수 있습니다.
조금 더 상세히 살펴보면, 클라이언트는 데이터를 read혹은 write할 때, 메타데이터를 얻기 위해 네임 노드와, 실제 사용자 데이터를 읽기/쓰기위해 데이터 노드와 통신합니다. 처음에 클라이언트가 데이터를 HDFS에 쓰기 위해서는 어디에 업로드 해야하는지 알아야 하고 이 정보는 오직 네임 노드에서 메타데이터를 얻어와야만 알 수 있습니다. 따라서 업로드 하고자 하는 파일의 정보를 네임 노드에게 요청하게 되고, 요청을 받은 네임 노드는 특정 데이터 노드를 선정하여 해당 정보를 클라이언트에게 전송합니다. 이 정보를 받은 클라이언트는 직접 데이터 노드와 통신하여 업로드 과정을 마무리합니다.
Heartbeat과 Re-replication : 보통 이런 분산 클러스터들은 일정한 주기로 하트비트를 전송(기본값 3초)하여 자신이 동작 중임을 알려주게 됩니다. 하둡의 경우에는 데이터 노드에서 네임 노드로 하트비트를 전송하게 되고, 네임 노드가 이를 받아 각 데이터 노드의 자원과 동작여부, 동작하지 않는 서버의 차단 등을 실행합니다.
특정 데이터 노드에서 문제가 발생한 경우, 네임 노드에서 데이터 전송을 처리 및 해당 데이터 노드에 저장된 블록들은 사용 불가능하다고 판정하게 되고, 다른 데이터 노드에 복제되어 있던 블록을 가지고 설정된 기본 복제 수(기본값 3)에 맞게 다른 데이터 노드에 저장하게 됩니다.
Data re-balancing : 하둡에 추가로 데이터 노드를 붙이는 경우, 기존에 존재하는 데이터 노드에는 데이터가 존재하고, 추가된 노드에는 데이터가 없게 됩니다. 이 상태로는 읽기/쓰기에 불균형이 생기므로, 효율적인 병렬 처리를 위하여 기존 블록들을 신규 데이터 노드에 옮기는 작업을 합니다. 데이터 재 배치를 하게 되면 읽기/쓰기가 균형이 맞게 되므로 이용률을 고르게 할 수 있지만 재 배치를 수행하는 동안은 데이터 노드와 네트워크에 부하가 발생할 수 밖에 없습니다. 따라서 이 작업은 자동으로는 이루어지지 않고 수동으로만 동작 가능합니다.
2) 세컨더리 네임 노드(Secondary Name Node)
- 앞서 네임 노드에 모든 메타데이터들이 저장된다고 말씀드렸습니다. 그렇다면 이 네임 노드에 문제가 생겨서 다운된다면 어떻게 될까요?
- 이와 같이 네임 노드가 다운된다면 디렉토리 구조 및 블록의 정보를 잃게 되는데 이를 SPoF(Single Point of Failure)문제가 있다 라고 합니다.
- 네임 노드에서는 모든 메타데이터 관련 명령 수행 목록을 Edits라는 파일에 기록하도록 되어 있는데요. 이 기법은 ext4에서 적용된 journaling이라는 기법과 동일합니다. 평소에 문제가 생기면 이 파일을 이용해서 메타데이터를 복구할 수 있습니다.
- 하지만 이 Edit파일도 너무 많이 쌓이게 되면 그만큼 처리하는데 많은 시간이 필요하게 됩니다. 이 문제를 해결하기 위해서 FsImage파일이 있는데, 이 FsImage파일은 Edits파일을 병합하여 불필요한 내용을 지우고 빠르게 복구할 수 있도록 합니다.
- 세컨더리 네임 노드에서는 네임 노드가 다운되었을 때, 그 자리를 대신하는게 아니라 Edits파일을 이용해서 주기적으로 FsImage파일을 병합하는 역할을 합니다. 이 작업을 checkpoint라고 하는데 이 이유로 '세컨더리 네임 노드'를 '체크포인트 노드' 라고 하기도 합니다.
- 다른 노드들과는 전혀 통신하지 않고, 일정 시간이 되었을때, 또는 네임 노드의 Edits파일의 크기가 지정한 크기보다 커지면 Edits파일을 가져와서 병합하여 FsImage파일을 만들고, 이를 다시 네임 노드로 넘겨줍니다. 물론 이 조건들은 변경 가능합니다.
3) 데이터 노드(Data Node)
- 데이터 노드에서는 사용자의 데이터를 실제로 저장합니다. 커다란 파일을 처리하기 위하여 블록이라는 단위로 파일을 잘라 분산 저장한다고 말씀드렸습니다. HDFS에서는 블록이 할당되어도 블록 크기만큼 쓰지 않으면 블록 크기만큼 유지되는 것이 아니라 해당 파일의 크기만큼만 할당됩니다. 이제 데이터 노드에서의 읽기/쓰기와 복제되는 과정을 알아보겠습니다.
- Data read :
- 어플리케이션이 클라이언트에게 특정 경로에 있는 파일을 요청
- 클라이언트에서 네임 노드에게 해당 파일의 블록이 있는 위치를 요청
- 네임 노드에서 블록 리스트가 담긴 메타데이터를 클라이언트에 전송
- 클라이언트는 블록 리스트를 통해서 데이터 노드에 접근하여 해당 블록 요청
- 데이터 노드가 해당 블록 전송
- 클라이언트가 어플리케이션에 해당 파일 전달
- Data write / replication : HDFS에서는 사용자가 파일을 업로드하는 동시에 여러 데이터 노드에 존재할 수 있도록 복제를 수행하게 됩니다. 복제를 수행하는 과정에서도 데이터를 유지하기 위해서 복제 파이프라이닝을 사용하는데 그 순서는 아래와 같습니다.
- 클라이언트가 데이터를 전송하기 위해서 네임 노드에 파일 업로드 요청
- 네임 노드가 특정 블록을 업로드 할 데이터 노드의 정보를 알려줌
- 첫번째 데이터 노드에 블록 업로드
- 첫번째 데이터 노드에서 복제를 수행할 다른 데이터 노드로 블록 복제 (복제 수에 따라 해당 단계 반복)
- 복제가 완료되었을 경우, 자신에게 복제를 요청한 데이터 노드로 완료 응답
- 파일이 모두 데이터 노드에 올라갈 때까지 2~4번 반복