우분투 16.04 및 14.04 에서도 cron이 실행될 때 로그를 남기도록 되어있지는 않게 되어있습니다.
아래 내용을 적용하면 cron이 동작할 때마다 로그를 남기게 됩니다.
$ sudo vi /etc/rsyslog.d/50-default.conf
파일을 열어보면 cron.* 항목이 주석으로 막혀있고 이를 해제하면 됩니다.
$ service rsyslog restart
$ service cron restart
우분투 16.04 및 14.04 에서도 cron이 실행될 때 로그를 남기도록 되어있지는 않게 되어있습니다.
아래 내용을 적용하면 cron이 동작할 때마다 로그를 남기게 됩니다.
$ sudo vi /etc/rsyslog.d/50-default.conf
파일을 열어보면 cron.* 항목이 주석으로 막혀있고 이를 해제하면 됩니다.
$ service rsyslog restart
$ service cron restart
기존에 있던 서버가 하드가 맛이 가면서 안에 있던 인증 내용이랑 웹서버 복구를 하게 되었다 -_-
다행이 하드가 아예 맛이 간건 아니고 일부 블록에 문제가 생기면서 커널 패닉이 발생하는 상황
원래 교체작업이 예정에 있었던 터라 부랴부랴 신규 서버를 셋팅하기로 했습니다.
우분투를 설치하고 아파치 셋팅 파일을 옮겨와서 설정 해주고 나니 남은건 디비 복구!
기존에 설치되어있던 mysql이 고스란히 있긴 한데 어어어어엄청 옛날 서버라서 그냥 데이터 파일을 가지고 복구를 진행해보기로 했습니다.
MySQL의 기본 데이터 저장소는 /var/lib/mysql 이며, 해당 디렉토리 내부에 데이터베이스 별로 디렉토리가 생성되어 있습니다.
해당 디렉토리 내부에 테이블 별로 frm및 ibd 파일이 존재하고 이 파일을 이용해서 복구를 하면되는데, mysqlfrm 커맨드로 frm 파일들을 조사해서 스키마 정보를 뽑아올 수 있습니다.
mysqlfrm커맨드는 기본 mysql패키지에는 포함 되어있지 않고, mysql-utilities 패키지를 설치해야 사용할 수 있습니다.
스키마 정보로 테이블을 생성 후, 테이블 스페이스를 폐기하고 기존의 ibd파일을 옮겨 다시 import하면 끝입니다.
$ sudo apt-get install mysql-utilities
$ sudo /var/lib/mysql/[Database]/*.frm > create_table.sql
$ mysql -r root -p
mysql> source create_table.sql;
mysql> alter table [Database].[Table] discard tablespace;
mysql> quit;
$ sudo cp /old_mysql/*.ibd /var/lib/mysql/[Database]
$ sudo chown mysql:mysql /var/lib/mysql/[Database]/*.ibd
$ mysql -u root -p
mysql> alter table [Database].[Table] import tablespace;
기존 row_format과 값이 다른 경우
ERROR 1808 (HY000): Schema mismatch (Table has ROW_TYPE_DYNAMIC row format, .ibd file has ROW_TYPE_COMPACT row format.)
라는 오류가 발생할 수 있습니다. 이럴 경우 테이블을 생성할 때 row_format=compact 값을 넣어주면 됩니다.
CREATE TABLE `table` (
`no` bigint(20) NOT NULL AUTO_INCREMENT,
`id` varchar(150) NOT NULL,
PRIMARY KEY `PRIMARY` (`no`)
) ENGINE=InnoDB row_format=compact;
HDFS를 정리해 봤으니 이제 YARN을 정리해봅니당

머리속에 다시금 새기기 위해 정리가 필요하여 남겨봅니다.
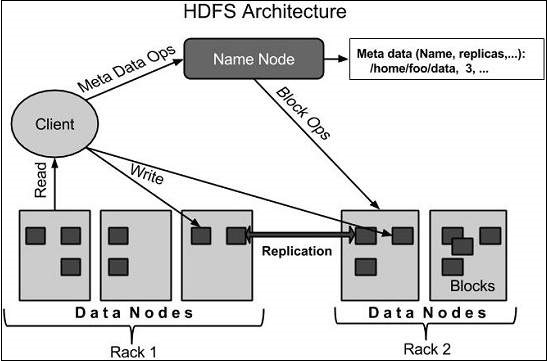
데이터 노드 정보 : 블록들을 잃어버리지 않기 위해 replica를 생성하는데 이런 블록들이 저장되는 데이터 노드의 위치 정보가 저장됩니다.
데이터 노드들의 상태 정보를 유지하고 관리합니다.
현재 HDFS에 등록되어 있는 데이터 노드의 목록과 현재 동작이 가능하지 등을 지속적으로 heartbeat를 통해 관리하게 되고 이 정보를 이용해서 새롭게 추가되는 데이터 블록이 어디에 저장되어야 하는지, replication이 제대로 이루어지고 있는지 등을 알아낼 수 있습니다.
조금 더 상세히 살펴보면, 클라이언트는 데이터를 read혹은 write할 때, 메타데이터를 얻기 위해 네임 노드와, 실제 사용자 데이터를 읽기/쓰기위해 데이터 노드와 통신합니다. 처음에 클라이언트가 데이터를 HDFS에 쓰기 위해서는 어디에 업로드 해야하는지 알아야 하고 이 정보는 오직 네임 노드에서 메타데이터를 얻어와야만 알 수 있습니다. 따라서 업로드 하고자 하는 파일의 정보를 네임 노드에게 요청하게 되고, 요청을 받은 네임 노드는 특정 데이터 노드를 선정하여 해당 정보를 클라이언트에게 전송합니다. 이 정보를 받은 클라이언트는 직접 데이터 노드와 통신하여 업로드 과정을 마무리합니다.
Heartbeat과 Re-replication : 보통 이런 분산 클러스터들은 일정한 주기로 하트비트를 전송(기본값 3초)하여 자신이 동작 중임을 알려주게 됩니다. 하둡의 경우에는 데이터 노드에서 네임 노드로 하트비트를 전송하게 되고, 네임 노드가 이를 받아 각 데이터 노드의 자원과 동작여부, 동작하지 않는 서버의 차단 등을 실행합니다.
특정 데이터 노드에서 문제가 발생한 경우, 네임 노드에서 데이터 전송을 처리 및 해당 데이터 노드에 저장된 블록들은 사용 불가능하다고 판정하게 되고, 다른 데이터 노드에 복제되어 있던 블록을 가지고 설정된 기본 복제 수(기본값 3)에 맞게 다른 데이터 노드에 저장하게 됩니다.
Data re-balancing : 하둡에 추가로 데이터 노드를 붙이는 경우, 기존에 존재하는 데이터 노드에는 데이터가 존재하고, 추가된 노드에는 데이터가 없게 됩니다. 이 상태로는 읽기/쓰기에 불균형이 생기므로, 효율적인 병렬 처리를 위하여 기존 블록들을 신규 데이터 노드에 옮기는 작업을 합니다. 데이터 재 배치를 하게 되면 읽기/쓰기가 균형이 맞게 되므로 이용률을 고르게 할 수 있지만 재 배치를 수행하는 동안은 데이터 노드와 네트워크에 부하가 발생할 수 밖에 없습니다. 따라서 이 작업은 자동으로는 이루어지지 않고 수동으로만 동작 가능합니다.
iOS에서 빌드 시, 빌드 창(?)에 copying swift standard libraries 진행 중에 아이디랑 비번을 계속 물어볼 때가 있다.
해당 내용은 개발자 인증서에 관련된 문제로, stackoverflow에서 해답을 찾을 수 있었다.
http://stackoverflow.com/questions/9738298/xcode-asking-username-password-everytime-i-compile-to-device
요약해서 말하자면, 개발자 인증서를 keychain system category에 넣어놓은 경우, 매번 codesigning을 할 때마다 아이디/비번을 물어오게 된다. 해결 방법은 developer certification을 login category에 넣으면 간단하게 해결된다 -_-.....
만약, 로그인에도 동일한 ('비슷한'이 아니다.) certification이 있을 경우, system에 있는 인증서를 걍 지우면 된다....
어찌보면 당연한 얘기이긴 한데...예부터 보자(돌려보진 않고 막 짠 코드)
void* testFunc(void* arg) {
...
}
int main() {
pthread_t p_thread[5];
int status[5];
int arg[5] = { 0, 1, 2, 3, 4 };
for (int i = 0; i < 5; i++) {
int thread_id = pthread_create(&p_thread[i], NULL, testFunc, (void *)(&(arg[i])));
}
for (int i = 0; i < 5; i++) {
pthread_join(p_thread[i], reinterpret_cast<void **>(&status[i]));
}
64bit에서는 요런식으로 pthread_join을 하게 되면 status가 4byte인 포인터를 넘겨주었는데
이대로 실행을 하게 되면 pthread_join()내부에서 8byte의 값으로 덮어쓰게 된다.
따라서 stack corrupted 오류가 발생하거나, 이상한 값이 들어올 수 있당
따라서 status를 8byte인 long long같은 형식으로 정의하면 된당
안드로이드 에뮬레이터를 콘솔에서 작업해야 할 때도 생긴당....
그럴 때 유용한 콤보를 알아보자.
- SD카드 생성
$ mksdcard <size> <file>
adb [<options>]
C++에서 32비트와 64비트를 #ifdef를 사용해서 정의하는 방법을 설명
결국 리눅스와 윈도우를 한꺼번에 가져갈 수는 없구만...
http://stackoverflow.com/questions/1505582/determining-32-vs-64-bit-in-c
허망하도다 -_-;
모르는걸 어째? 알면 되지 ㅋㅋㅋ
http://stackoverflow.com/questions/20669108/how-to-get-8-byte-pointer-value-on-64-bit-machine-on-gdb
$ git config --global credential.helper cache
시간 설정 가능
$ git config --global credential.helper 'cache --timeout=3600'